⭐ Plogramming/BigData
Chapter 2. 하둡 아키텍쳐
김진한
2023. 7. 2. 17:47
1. 하둡 아키텍쳐

- 하둡 클러스터
- HDFS과 얀(클러스터 리소스 매니저)를 기반으로 하는 하둡 SW를 사용하는 컴퓨터들의 집합체
- 마스터 노드: 클러스터의 작업을 중재
- 워커 노드: 마스터의 명령을 수행하며 데이터가 저장되고 프로세싱
- 하둡 서비스
- HDFS 서비스
- 얀 서비스
2. HDFS 아키텍처
- 데이터 스토리지
- 특징
- 대용량 데이터 세트 다루기
- 장애 허용
- 기본적으로 3번 복제가 되어 다른 노드에 데이터가 저장되기 때문에 장애 서버의 영향을 받지 않는다. (서버의 병렬화)
- 데이터 스트리밍
- 배치 프로세싱을 위해 디자인되었으며 데이터 세트에 대해 스트리밍 접속이 가능하도록 만들어졌다.
- 단순 데이터 일관성 모델
- WORM(Wite Once Read Many access model)로 하나의 주체만 기록할 수 있다.
- 마스터 노드
- 네임 노드(HDFS 메타데이터를 관리)나 리소스 매니저(잡이나 태스크 관리)같은 핵심 서비스가 실행
- 메타데이터 유지 -> 메모리에 저장
- 사용자 접속 관리
- 데이터 노드에 매핑
- 어떤 노드를 복제하고 삭제할지 결정
- 네임 노드 오퍼레이션
- 메타데이터를 fsimage 파일로 디스크에 저장
- 세컨더리 네임 노드
- 클러스터를 멈추지 않고 주기적으로 fsimage 파일의 체크포인트를 실행 -> edit 파일(fsimage 파일의 로그 파일)로 통합 -> 네임 노드에 업데이트 정보 제공
- 스탠바이 네임 노드
- 사용하던 네임 노드(액티브 네임 노드)가 장애 노드가 될 경우 자동으로 실행 -> 고가용성
- 워커 노드(데이터 노드)
- 노드매니저(얀)을 실행
- 로컬에 저장하는 방식으로 블록 스토리지 서비스를 제공
- 데이터에 대한 읽기.쓰기 기능
- 데이터 블록 생성.삭제
- 데이터 복제
- HDFS 파일 시스템
- 파일 블록은 무작위로 클러스터에 분산 저장
- 파일을 작성하면 수정할 수 없으나, 이동/삭제/이름 변경은 가능
- 바이너리 포맷의 데이터 -> 불완전한 레코드가 생성되는 것을 막을 수 있음
- SequenceFile(키-값 목록으로 표현)의 포맷도 사용
- 하둡 자체 라이브러리를 사용하면, HDFS 데이터에 직접 접근 가능(외에는 로컬센터의 랙에서 데이터를 읽도록 함)
- 불균형 데이터 가능성
- 분산 저장되는 데이터들이 시간이 지날 수록 불균형을 이루게 됨

4. 얀 아키텍처
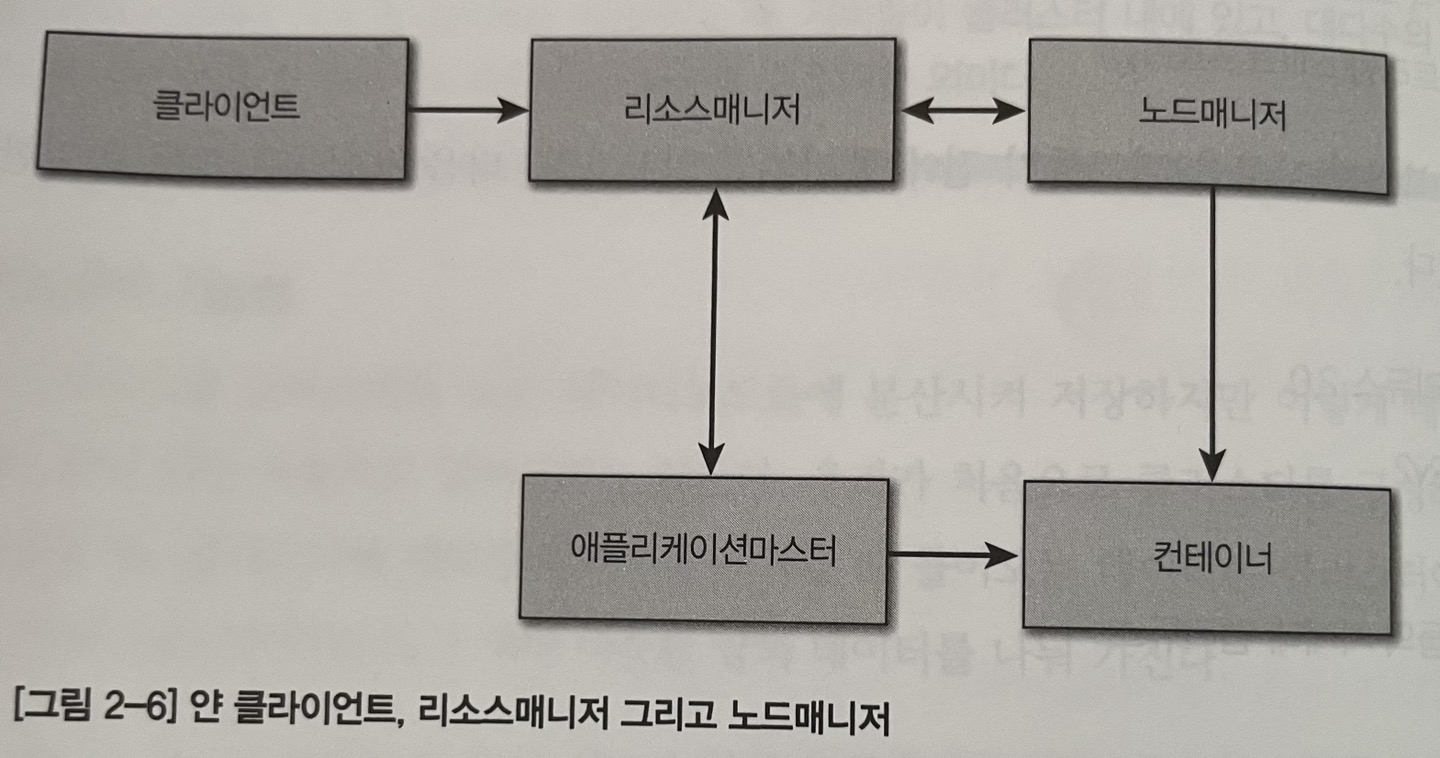

- 얀 컨테이너
- 메모리와 cpu와 같은 다른 리소스의 양을 구체적으로 표현하는 논리적 구조
- 태스크가 시작할 때 생성되어 완료되면 소멸된다. -> 갖고 있던 리소스는 다른 태스크에 할당
- 리소스매니저
- 클러스터마다 하나만 존재
- 컨테이너를 각 애플리케이션에 할당 -> 컨테이너를 스케줄링
- 데이터 노드의 리소스 할당
- 스케줄러 & 애플리케이션 매니저
- 노드매니저
- 컨테이너의 라이프 사이클을 관리
- 애플리케이션을 시작하고 리소스 매니저와 정보를 주고 받음
- 로그 관리
- 데이터 노드의 상태 추적
- 애플리케이션마스터
- 얀 애플리케이션에는 하나의 전용 애플리케이션 마스터가 있음
- 태스크 스케줄링과 실행 관리
- 애플리케이션 태스크를 위해 로컬 리소스 할당
- 잡 히스토리 서버
- 전체 클러스터에 하나만 존재
- 얀 컴포넌트 간의 협업