🏫CS/데이터베이스
Replication 과 Clustering
김진한
2023. 5. 7. 17:06
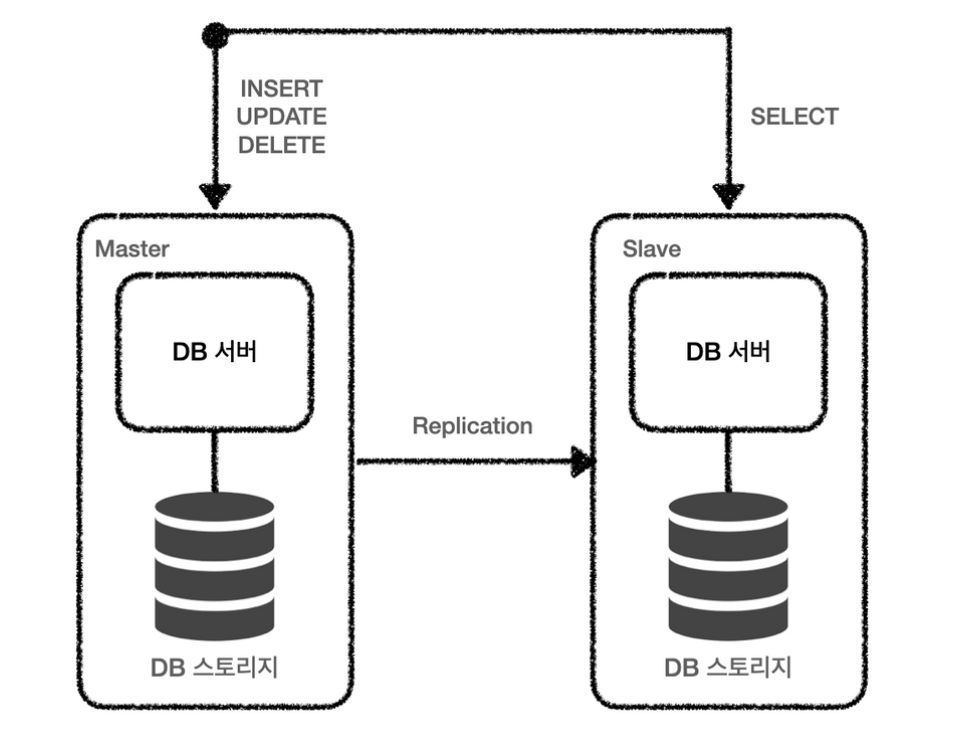
Replication
: 2개 이상의 DBMS 시스템을 수직적(master: 쓰기 / slave: 읽기)로 나눠서 동일한 데이터를 저장
- 읽기 작업이 DB의 주 성능이라 good!
- 지연 시간 X(비동기)
- 동기화 X (일관성 x)
- master 노드가 다운될 시 그것은 죽음 뿐,,,,,ㅠㅠ
* 처리 순서
1) Master Node
- 쓰기 트랜잭션 수행
2) Master Node
- 데이터 저장
- 쓴 트랜잭션을 로그 파일에 저장
3) Slave Node
- io 스레드는 로그 파일을 file에 복사
4) Slave Node
- SQL 스레드는 파일을 한 줄씩 읽으면서 데이터에 저장
Clustering
: 여러 DBMS를 수평적으로 구축하는 방식으로, 동기 방식으로 노드들 간의 데이터 동기화(데이터 무결성 검사)
- 노드들 간의 동기화로 일관된 데이터 구축
- 1개 죽어도 다른 노드가 있으니까 다행
- 동기화 시간이 길다
* 처리 순서
1) 1개 노드에 쓰기 트랜잭션 수행 -> commit
2) 다른 노드로 데이터 복제 요청
3) 복제 요청 수락 -> 디스크에 쓰기
4) 다른 노드들로부터 수락 신호받으면 실제 디스크에 데이터 저장
